Overview & Architecture
PostgreSQL is famously reliable, but out of the box it has no built-in automatic failover. If the primary server dies, nothing promotes a standby for you. High availability is therefore assembled from a few well-defined layers:
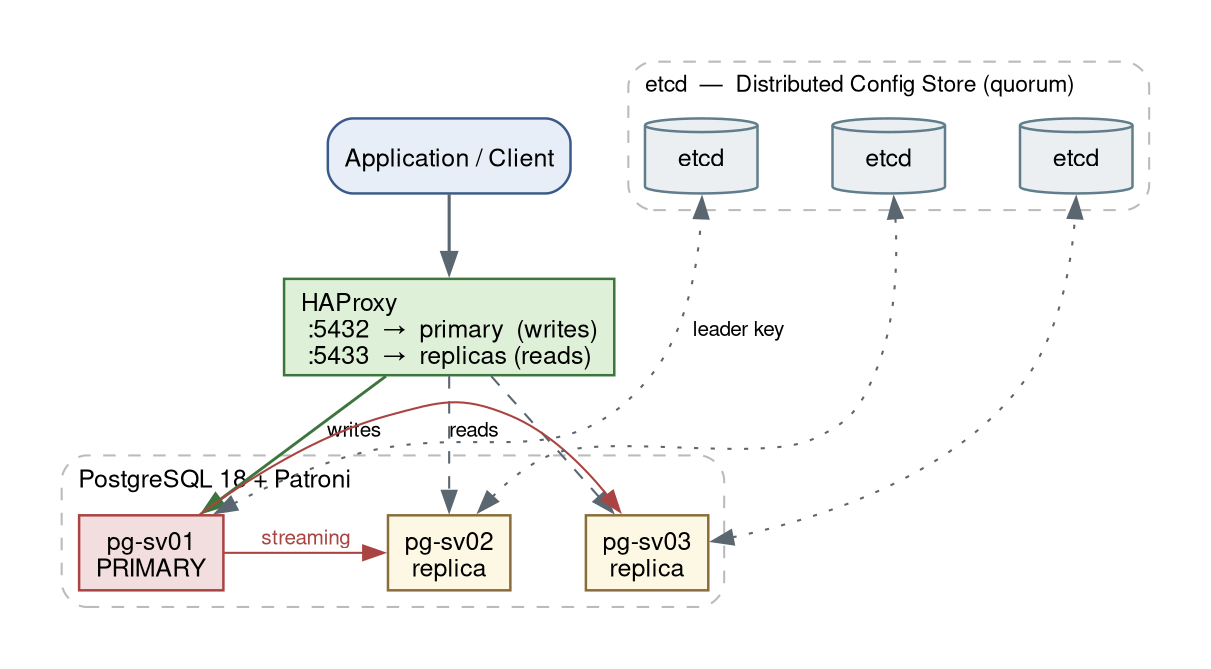
- Streaming replication — one primary and N hot-standby replicas kept in sync via the write-ahead log (WAL).
- Patroni — the orchestrator. It bootstraps PostgreSQL, runs leader election, promotes a standby when the primary fails, and exposes a REST API describing cluster state.
- etcd — the distributed configuration store (DCS). It holds the cluster state and provides the quorum that decides who the leader is, preventing split-brain.
- HAProxy — the client entry point. It sends writes to the current primary and reads to the replicas, following Patroni's health checks.
Architecture
| Layer | Component | Role |
|---|---|---|
| Data | PostgreSQL 18 | The database + streaming replication |
| Orchestration | Patroni | Leader election, automatic failover, REST API |
| Consensus | etcd (3-node) | Quorum / cluster state (the DCS) |
| Routing | HAProxy | RW → primary, RO → replicas |
What we will build
A 3-node PostgreSQL cluster (one primary + two replicas) with etcd co-located on the database nodes, fronted by a dedicated HAProxy node:
pg-sv01,pg-sv02,pg-sv03— PostgreSQL 18 + Patroni + etcdpg-haproxy— HAProxy entry point
Three nodes is the minimum for a real cluster: the quorum (more than half) survives the loss of one node, and an odd number avoids split-brain.
The end result
When the primary fails, Patroni elects a new leader within seconds, and HAProxy transparently repoints the write port to it — the application keeps working with no manual intervention and no failover logic of its own. We finish by proving exactly that with a hard-kill failover test.
Heads-up: every password in this guide is a placeholder. Replace them all with your own strong secrets before using this anywhere real.
No comments to display
No comments to display